
Documento Confidencial
Autor: Daniel Davila Lopez
Daniel Davila Lopez
PowerShell, Envio de emails
Documento Confidencial
Oracle Cliente, Errors
Si al instalar el cliente de Oracle te aparece un error prvg-11322
que corresponde al nombre del host donde lo estas instalando y que contiene caracteres no permitidos (_)
Podemos saltarnos la parte de validaciones con el siguiente comando
-- setup.exe -ignorePrereq -J"-Doracle.install.client.validate.clientSupportedOSCheck=false" --
Link de ayuda
https://dba.stackexchange.com/questions/52645/oracle-12c-installation-in-windows-7-error-ins-30131
Oracle Client, Error INS-30131 Instalación
Al instalar el cliente de 32 y/o 64Bits aparece el siguiente error
SEVERE: [FATAL] [INS-30131] Initial setup required for the execution of installer validations failed. CAUSE: Failed to access the temporary location. ACTION: Ensure that the current user has required permissions to access the temporary location. *ADDITIONAL INFORMATION:* - Framework setup check failed on all the nodes - Cause: Cause Of Problem Not Available - Action: User Action Not Available Summary of the failed nodes maddy-pc - Version of exectask could not be retrieved from node "XXXXXX" - Cause: Cause Of Problem Not Available - Action: User Action Not Available
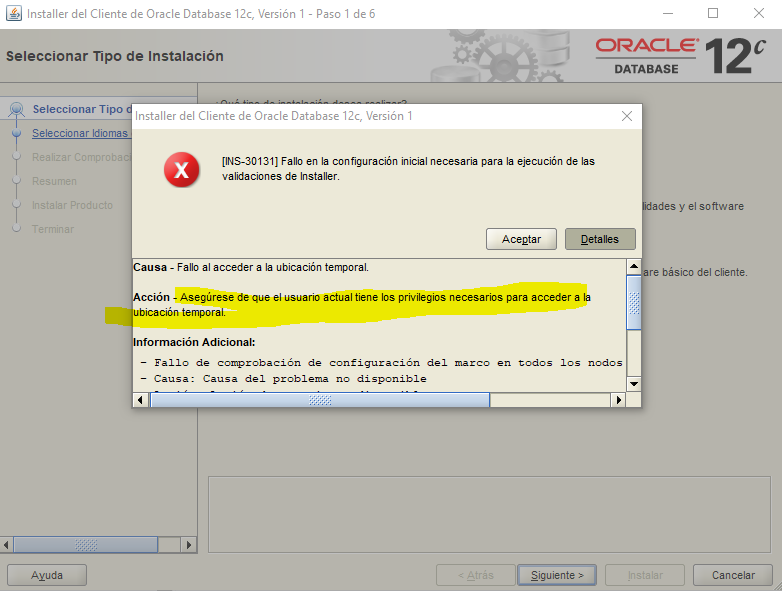
SOLUCIÓN:
client installs, run the installer
setup.exe -ignorePrereq -J"-Doracle.install.client.validate.clientSupportedOSCheck=false"
For server installs, run the installer
setup.exe -ignorePrereq -J"-Doracle.install.db.validate.supportedOSCheck=false"
SQL, Números aleatorios
Método 1 : Generar un número aleatorio entre un rango
---- Create the variables for the random number generation DECLARE @Random INT; DECLARE @Upper INT; DECLARE @Lower INT ---- This will create a random number between 1 and 999 SET @Lower = 1 ---- The lowest random number SET @Upper = 999 ---- The highest random number SELECT @Random = ROUND(((@Upper - @Lower -1) * RAND() + @Lower), 0) SELECT @Random
Método 2 : Generar un número aleatorio flotante
SELECT RAND( (DATEPART(mm, GETDATE()) * 100000 ) + (DATEPART(ss, GETDATE()) * 1000 ) + DATEPART(ms, GETDATE()) )
Método 3 : Generar un número aleatorio rápido
---- random float from 0 up to 20 - [0, 20) SELECT 20*RAND() -- random float from 10 up to 30 - [10, 30) SELECT 10 + (30-10)*RAND() --random integer BETWEEN 0 AND 20 - [0, 20] SELECT CONVERT(INT, (20+1)*RAND()) ----random integer BETWEEN 10 AND 30 - [10, 30] SELECT 10 + CONVERT(INT, (30-10+1)*RAND())
Método 4 : Números aleatorios (Float, Int) Tablas basadas en tiempo
DECLARE @t TABLE( randnum float ) DECLARE @cnt INT; SET @cnt = 0 WHILE @cnt <=10000 BEGIN SET @cnt = @cnt + 1 INSERT INTO @t SELECT RAND( (DATEPART(mm, GETDATE()) * 100000 ) + (DATEPART(ss, GETDATE()) * 1000 ) + DATEPART(ms, GETDATE()) ) END SELECT randnum, COUNT(*) FROM @t GROUP BY randnum
Método 5 : Número aleatorio por fila
---- The distribution is pretty good however there are the occasional peaks. ---- If you want to change the range of values just change the 1000 to the maximum value you want. ---- Use this as the source of a report server report and chart the results to see the distribution SELECT randomNumber, COUNT(1) countOfRandomNumber FROM ( SELECT ABS(CAST(NEWID() AS binary(6)) %1000) + 1 randomNumber FROM sysobjects) sample GROUP BY randomNumber ORDER BY randomNumber
Documento original:
https://blog.sqlauthority.com/2007/04/29/sql-server-random-number-generator-script-sql-query/
Oracle, Script, conceptos y chunches
Empezaremos a recolectar información acerca de Oracle de acuerdo como se nos va presentando las cosas en el proyecto JDA, la primera situación que se nos presento es el manejo de espacio para los TableSpace
Este script nos informa de los tamaños y objetos por bloque que contiene los TableSpaces
-- SELECT tablespace_name, ROUND(sum(bytes)/1024/1024,0) FROM dba_free_space WHERE tablespace_name NOT LIKE 'TEMP%' GROUP BY tablespace_name; SELECT TABLESPACE_NAME "TABLESPACE", FILE_ID, COUNT(*) "PIECES", MAX(blocks) "MAXIMUM", MIN(blocks) "MINIMUM", AVG(blocks) "AVERAGE", SUM(blocks) "TOTAL" FROM DBA_FREE_SPACE GROUP BY TABLESPACE_NAME, FILE_ID; --
Para ver el tamaño de un Tablespace
SELECT tablespace_name, file_name, bytes/(1024*1024) AS "[Mb]" FROM dba_temp_files WHERE tablespace_name like 'TEMP%';
Tamaño de los Volumens donde esta las basedata
select name,state,total_mb,free_mb from v$asm_diskgroup; select group_number, name, path, os_mb, total_mb, free_mb from v$asm_disk; select * from v$asm_disk;
Para ver cuantos TableSpace existen
SELECT * FROM V$TABLESPACE
Para crear TableSpaces
-- CREATE TABLESPACE TS_SSIDATA DATAFILE '+DATA1/SSCALDEV/69F98A6850942F46E053B60110ACC7DF/DATAFILE/TS_SSIDATA.dbf' SIZE 500M; CREATE TABLESPACE TS_SSIIDX DATAFILE '+DATA1/SSCALDEV/69F98A6850942F46E053B60110ACC7DF/DATAFILE/TS_SSIIDX.dbf' SIZE 500M; --
Para modificar tableSpaces
-- ALTER DATABASE datafile '+DATA1/SSCALDEV/69F98A6850942F46E053B60110ACC7DF/DATAFILE/TS_SSIDATA.dbf' resize 2048M; ALTER DATABASE datafile '+DATA1/SSCALDEV/69F98A6850942F46E053B60110ACC7DF/DATAFILE/TS_SSIIDX.dbf' resize 2048M; commit --
La forma más exacta de saber lo que “realmente” está consumido de los data files es sumando los bytes de la DBA_EXTENTS:
-- Select Tablespace_name, Sum(bytes) total From Dba_extents Group by Tablespace_name; Select Tablespace_name, Sum(bytes) total From Dba_data_files Group by Tablespace_name; --
Mostrar los nombres de las tablas que están en un TableSpace
-- select owner,TABLE_NAME,TABLESPACE_NAME from dba_tables where TABLESPACE_NAME = 'TS_SSIDATA' select TABLE_NAME from dba_tables where TABLESPACE_NAME = 'TS_SSIDATA' --
Tu puedes utiliza el siguiente código para recuperar el tamaño por tabla en un esquema, para un tamaño total retira la condición que el objeto sea tabla
SELECT segment_name AS "TABLE_NAME", SUM (BYTES) AS "[Bytes]", SUM (BYTES) / 1024 AS "[Kb]", SUM (BYTES) / (1024*1024) AS "[Mb]", SUM (BYTES) / (1024*1024*1024) AS "[Gb]" FROM user_segments WHERE segment_type = 'TABLE' GROUP BY segment_name; select owner, sum(bytes) / (1024*1024) AS "[Mb]" from dba_segments group by owner order by "[Mb]"
Sesiones
-- SET LINESIZE 100 COLUMN spid FORMAT A10 COLUMN username FORMAT A10 COLUMN program FORMAT A45 SELECT s.inst_id, s.sid, s.serial#, --s.sql_id, p.spid, s.username, s.program FROM gv$session s JOIN gv$process p ON p.addr = s.paddr AND p.inst_id = s.inst_id WHERE s.type != 'BACKGROUND'; --
Kill sesiones
alter system kill session '404,25431, @2' immediate; ALTER SYSTEM DISCONNECT SESSION '31,58911' immediate;
Espacio en discos
select group_number, name, path, os_mb, total_mb, free_mb from v$asm_disk; select name,state,total_mb,free_mb from v$asm_diskgroup;
Activar/Desactivar Archivelog de Oracle
El tener activado el Archivelog es el primer paso para poder realizar una copia en caliente de nuestra Base de Datos mediante Rman, a continuación explicaremos como activar/desactivar esta opción para tener otra opción más de realizar copias de seguridad de nuestra Base de Datos, aquí una pequeña explicación del modo archivelog.
El modo archivelog de una base de datos Oracle protege contra la pérdida de datos cuando se produce un fallo en el medio físico.
- Se puede realizar una copia de seguridad mientras la base de datos está levantada.
- Con este modo de base de datos se puede restaurar una copia de seguridad de los archivos dañados utilizando estos archivos para actualizar los archivos mientras nuestra base de datos está levantada.
- Se puede recuperar la base de datos en un número de cambio del sistema específico.
- Se puede restaurar la base de datos en un punto específico en el tiempo.
- Teniendo en cuenta estas características básicas del modo archivelog de base de datos ORACLE, vamos a exponer en este documento cómo se activa y cómo se desactiva.
Alguna de las consecuencias que tiene desactivarlo son las siguientes:
- Las copias de seguridad ya no se pueden hacer on-line (habría que aplicar otro tipo de copias de seguridad).
- No se podrá recuperar la base de datos en un tiempo concreto.
Lo primero que tenemos que saber si nuestra base de dato tiene activo o no el Archivelog, para verlo:
– Entramos en la consola de sqlplus e introducimos el siguiente comando archive log list, lo que nos dirá si tenemos o no activado el archivelog y si el archivado automático está funcionando
DESACTIVACIÓN DEL MODO ARCHIVELOG
Para desactivar el modo archivelog, realizamos los siguientes pasos:
– Nos conectamos a la base de datos y la paramos, despues de pararla la montamos
shutdown immediate
startup mount
– Desactivamos el modo archivelog
alter database noarchivelog
– Abrimos la base de datos
alter database open
– Desactivamos el archivado automático
alter system archive log stop
ACTIVACIÓN DEL ARCHIVELOG
– Para activar el modo archivelog, el init.ora debe de estar arrancado con los siguientes parámetros.
log_archive_start = true
log_archive_dest_1 = “location=/database/archivelog/bbdd REOPEN=5”
log_archive_format = arch_%t_%s.arc
– Si la base de datos está funcionando y esos parámetros están en el init.ora, nos conectamos a la base de datos y la paramos con un
shutdown immediate
– A continuación montamos la base de datos:
startup mount
– Cuando montamos la base de datos ejecutamos el siguiente comando:
alter database archivelog
– Despues abrimos nuestra base de datos y activamos el archivado automático
alter database open
alter system archive log start
Links de Interes
Administración de usuarios en Oracle Database
Gestión de Base de Datos
Activar/Desactivar Archivelog de Oracle
Cursores
show parameter pga_aggregate_limit; select * from V$SESSTAT select * from v$open_cursor show parameter cursor alter system set open_cursors=600; select s.username, max(a.value) from v$sesstat a, v$statname b, v$session s where a.statistic# = b.statistic# and s.sid (+)= a.sid and b.name = 'opened cursors current' group by s.username
JDA, Errores
Documento Confidencial
Contenedores, Prerrequisitos
La caracteristica de «Conteiners» esta habilitada desde windows 2016 server build 1709
El rol Hyper-V debe estar instalado antes de ejecutar Hyper-V Cointeners
Windows server Conteiners hosts debera estar instalado en C:.
Documento Confidencial
Contenedores: Docker, Windows y Tendencias
Por: Mark Russinovich CTO, Microsoft Azure
No se puede debatir sobre la computación en la nube últimamente sin hablar de contenedores. Las organizaciones de todos los segmentos comerciales, desde bancos y grandes empresas de servicios financieros hasta sitios de comercio electrónico, quieren saber qué son los contenedores, qué significan para las aplicaciones en la nube y cómo usarlos mejor para su desarrollo específico y escenarios de operaciones de TI. Desde los conceptos básicos de qué son los contenedores y cómo funcionan, hasta los escenarios en los que se usan más ampliamente hoy, las tendencias emergentes que apoyan la «contenedorización», pensé que compartiría mis perspectivas para ayudarlo a comprender mejor cómo abrazar mejor este importante desarrollo de la computación en la nube para construir, probar, implementar y administrar sus aplicaciones en la nube de manera más uniforme.
Resumen de contenedores
En términos abstractos, toda la informática se basa en ejecutar alguna «función» en un conjunto de recursos «físicos», como procesador, memoria, disco, red, etc., para realizar una tarea, ya sea un cálculo matemático simple, como 1+ 1, o una aplicación compleja que abarca varias máquinas, como Exchange. Con el tiempo, a medida que los recursos físicos se hicieron más y más poderosos, a menudo las aplicaciones no utilizaban ni una fracción de los recursos proporcionados por la máquina física. Por lo tanto, se crearon recursos «virtuales» para simular el hardware físico subyacente, lo que permite que varias aplicaciones se ejecuten simultáneamente, cada una de las cuales utiliza fracciones de los recursos físicos de la misma máquina física. Comúnmente nos referimos a estas técnicas de simulación como virtualización. Si bien muchas personas piensan de inmediato en máquinas virtuales cuando oyen virtualización, esa es solo una implementación de la virtualización. La memoria virtual, un mecanismo implementado por todos los sistemas operativos de propósito general (OS), da a las aplicaciones la ilusión de que la memoria de una computadora está dedicada a ellas e incluso puede darle a una aplicación la experiencia de tener acceso a mucha más RAM de la que la computadora tiene disponible. Los contenedores son otro tipo de virtualización, también conocida como virtualización del sistema operativo. Los contenedores de hoy en Linux crean la percepción de un sistema operativo totalmente aislado e independiente para la aplicación. Para el contenedor en ejecución, el disco local se ve como una copia prístina de los archivos del sistema operativo, la memoria solo aparece para contener archivos y datos de un sistema operativo recién iniciado, y lo único que se ejecuta es el sistema operativo. Para lograr esto, la máquina «host» que crea un contenedor hace algunas cosas inteligentes. La primera técnica es el aislamiento del espacio de nombres. Los espacios de nombre incluyen todos los recursos con los que una aplicación puede interactuar, incluidos los archivos, los puertos de red y la lista de procesos en ejecución.El aislamiento del espacio de nombres permite que el host le dé a cada contenedor un espacio de nombres virtualizado que incluye solo los recursos que debería ver. Con esta vista restringida, un contenedor no puede acceder a los archivos no incluidos en su espacio de nombres virtualizado, independientemente de sus permisos, ya que simplemente no puede verlos. Tampoco puede listar o interactuar con aplicaciones que no forman parte del contenedor, lo que lo engaña y le hace creer que es la única aplicación que se ejecuta en el sistema cuando puede haber docenas o cientos de otras. Para mayor eficiencia, muchos de los archivos del sistema operativo, directorios y servicios en ejecución se comparten entre contenedores y se proyectan en el espacio de nombres de cada contenedor. Solo cuando una aplicación realiza cambios en sus contenedores, por ejemplo modificando un archivo existente o creando uno nuevo, el contenedor obtiene copias distintas del sistema operativo host subyacente, pero solo se cambian esas partes, utilizando la función de copiar y escribir de Docker. «Optimización» Este intercambio es parte de lo que hace que la implementación de múltiples contenedores en un único servidor sea extremadamente eficiente. En segundo lugar, el host controla la cantidad de recursos del host que puede usar un contenedor. Los recursos gubernamentales, como la CPU, la RAM y el ancho de banda de la red, garantizan que un contenedor obtenga los recursos que espera y que no afecte el rendimiento de otros contenedores que se ejecutan en el host. Por ejemplo, un contenedor puede estar restringido para que no pueda usar más del 10% de la CPU. Eso significa que incluso si la aplicación dentro de ella intenta, no puede acceder al otro 90%, que el host puede asignar a otros contenedores o para su propio uso. Linux implementa dicha gobernanza utilizando una tecnología llamada «cgroups». La gobernanza de recursos no es necesaria en casos donde los contenedores colocados en el mismo host son cooperativos, lo que permite la asignación de recursos dinámicos estándar del SO que se adapta a las demandas cambiantes del código de la aplicación.La combinación de inicio instantáneo que proviene de la virtualización del sistema operativo y la ejecución confiable que proviene del aislamiento del espacio de nombres y la administración de los recursos hace que los contenedores sean ideales para el desarrollo y la prueba de aplicaciones. Durante el proceso de desarrollo, los desarrolladores pueden iterar rápidamente. Debido a que su entorno y el uso de recursos son consistentes en todos los sistemas, una aplicación en contenedor que funcione en un sistema de desarrollador funcionará de la misma manera en un sistema de producción diferente. El inicio instantáneo y el tamaño reducido también benefician a los escenarios en la nube, ya que las aplicaciones pueden escalar rápidamente y muchas más instancias de aplicación pueden caber en una máquina que si estuvieran en una VM, lo que maximiza la utilización de recursos. Comparar un escenario similar que usa máquinas virtuales con uno que usa contenedores resalta la eficiencia ganada por el intercambio. En el ejemplo que se muestra a continuación, la máquina host tiene tres máquinas virtuales. Para proporcionar a las aplicaciones en el aislamiento completo de las máquinas virtuales, cada una de ellas tiene sus propias copias de los archivos del sistema operativo, las bibliotecas y el código de la aplicación, junto con una instancia completa en la memoria de un sistema operativo. Iniciar una VM nueva requiere arrancar otra instancia del sistema operativo, incluso si el host o las VM existentes ya tienen instancias en ejecución de la misma versión y cargar las bibliotecas de aplicaciones en la memoria. Cada VM de aplicaciones paga el costo del arranque del sistema operativo y la huella en memoria de sus propias copias privadas, lo que también limita el número de instancias de aplicaciones (VM) que se pueden ejecutar en el host.

La figura siguiente muestra el mismo escenario con contenedores. Aquí, los contenedores simplemente comparten el sistema operativo del host, incluido el kernel y las bibliotecas, por lo que no necesitan iniciar un sistema operativo, cargar bibliotecas o pagar un costo de memoria privada para esos archivos. El único espacio incremental que toman es la memoria y el espacio en disco necesarios para que la aplicación se ejecute en el contenedor. Si bien el entorno de la aplicación se siente como un sistema operativo dedicado, la aplicación se despliega como lo haría en un host dedicado. La aplicación en contenedor comienza en segundos y muchas más instancias de la aplicación pueden caber en la máquina que en la carcasa de VM.

Apelación de Docker
El concepto de aislamiento del espacio de nombres y la gobernanza de los recursos relacionados con los SO ha existido durante mucho tiempo, volviendo a las Cárceles de BSD, a las Zonas de Solaris e incluso al mecanismo chroot (cambio de raíz) básico de UNIX. Sin embargo, al crear un conjunto de herramientas común, un modelo de empaque y un mecanismo de implementación, Docker simplificó enormemente la contenedorización y distribución de aplicaciones que luego pueden ejecutarse en cualquier lugar en cualquier host de Linux. Esta tecnología omnipresente no solo simplifica la administración al ofrecer los mismos comandos de administración contra cualquier host, sino que también crea una oportunidad única para DevOps sin problemas. Desde el escritorio de un desarrollador hasta una máquina de prueba y un conjunto de máquinas de producción, se puede crear una imagen Docker que se implementará de manera idéntica en cualquier entorno en segundos. Esta historia ha creado un ecosistema masivo y creciente de aplicaciones empaquetadas en contenedores Docker, con DockerHub, el registro público de aplicaciones en contenedores que Docker mantiene, que actualmente publica más de 180,000 aplicaciones en el repositorio comunitario público. Además, para garantizar que el formato de empaquetado siga siendo universal, Docker organizó recientemente la Iniciativa de contenedor abierto (OCI), con el objetivo de garantizar que el empaquetado de los contenedores siga siendo un formato abierto y basado en fundaciones, con Microsoft como uno de los miembros fundadores.
Servidor Windows y contenedores
Para llevar el poder de los contenedores a todos los desarrolladores, en octubre pasado anunciamos planes para implementar tecnología de contenedores en Windows Server. Para permitir a los desarrolladores que usan contenedores Docker de Linux con la misma experiencia en Windows Server, también anunciamos nuestra asociación con Docker para ampliar la API de Docker y el conjunto de herramientas para admitir Contenedores de servidor de Windows. Para nosotros, esta fue una oportunidad para beneficiar a todos nuestros clientes, tanto Linux como Windows por igual. Tal como lo demostré recientemente en DockerCon, estamos entusiasmados de crear una experiencia unificada y abierta para que los desarrolladores y administradores de sistemas implementen sus aplicaciones contenerizadas que incluyen Windows Server y Linux. Estamos desarrollando esto en el repositorio Docker GitHub abierto. En Windows Server 2016, lanzaremos dos sabores de contenedores, los cuales se podrán implementar utilizando las API de Docker y el cliente de Docker: Contenedores de Windows Server y Contenedores de Hyper-V. Los contenedores Linux requieren API de Linux del kernel de host y los contenedores de servidor de Windows requieren las API de Windows de un Kernel de Windows host, por lo que no puede ejecutar contenedores Linux en un servidor de Windows Server o un contenedor de servidor de Windows en un host de Linux. Sin embargo, el mismo cliente de Docker puede administrar todos estos contenedores, y aunque no puede ejecutar un contenedor de Windows empaquetado en Linux, un paquete de contenedor de Windows funciona con Contenedores de Windows Server y Contenedores de Hyper-V porque ambos utilizan el kernel de Windows. Existe la cuestión de cuándo es posible que desee utilizar un contenedor de servidor de Windows frente a un contenedor de Hyper-V. Si bien el intercambio de kernel permite una rápida puesta en marcha y un embalaje eficiente, los contenedores de servidor de Windows comparten el sistema operativo con el host y entre ellos. La cantidad de datos compartidos y API significa que puede haber formas, ya sea por diseño o debido a un error de implementación en el aislamiento del espacio de nombres o la gobernanza de los recursos, para que una aplicación escape de su contenedor o niegue el servicio al host u otros contenedores. La elevación local de vulnerabilidades de privilegios que el parche de proveedores de sistemas operativos es un ejemplo de un defecto que una aplicación podría aprovechar. Por lo tanto, los contenedores de servidor de Windows son ideales para escenarios donde el sistema operativo confía en las aplicaciones que se alojarán en él, y todas las aplicaciones también confían entre sí. En otras palabras, el sistema operativo host y las aplicaciones se encuentran dentro del mismo límite de confianza. Eso es cierto para muchas aplicaciones de varios contenedores, aplicaciones que componen un servicio compartido de una aplicación más grande y, a veces, aplicaciones de la misma organización. Sin embargo, hay casos donde es posible que desee ejecutar aplicaciones desde diferentes límites de confianza en el mismo host. Un ejemplo es si está implementando una oferta PaaS o SaaS multiusuario donde permite que sus clientes suministren su propio código para extender la funcionalidad de su servicio. No desea que el código de un cliente interfiera con su servicio u obtenga acceso a los datos de sus otros clientes, pero necesita un contenedor que sea más ágil que una VM y que aproveche el ecosistema de Docker. Tenemos varios ejemplos de dichos servicios en Azure, como Azure Automation y Machine Learning. Llamamos al entorno que ellos manejan en «multi-tenencia hostil», ya que tenemos que suponer que hay clientes que deliberadamente buscan subvertir el aislamiento. En este tipo de entornos, el aislamiento de los Contenedores de Servidor de Windows puede no proporcionar la seguridad suficiente, lo que motivó nuestro desarrollo de Contenedores de Hyper-V. Los contenedores Hyper-V adoptan un enfoque ligeramente diferente a la contenedorización. Para crear un mayor aislamiento, los contenedores de Hyper-V tienen cada uno su propia copia del kernel de Windows y tienen memoria asignada directamente a ellos, un requisito clave de un fuerte aislamiento. Usamos Hyper-V para CPU, memoria y aislamiento IO (como red y almacenamiento), ofreciendo el mismo nivel de aislamiento que se encuentra en las máquinas virtuales. Al igual que para las VM, el host solo expone una interfaz pequeña y restringida al contenedor para la comunicación y el intercambio de recursos de host. Esta compartición muy limitada significa que los Contenedores Hyper-V tienen menos eficiencia en tiempos de inicio y densidad que los Contenedores de Servidor de Windows, pero el aislamiento requerido para permitir que las aplicaciones no confiables y «hostiles multi-tenant» se ejecuten en el mismo host. Entonces, ¿no son los Contenedores Hyper-V lo mismo que las máquinas virtuales? Además de las optimizaciones para el sistema operativo que resultan de que es totalmente consciente de que está en un contenedor y no en una máquina física, Hyper-V Containers se implementará utilizando la magia de Docker y puede usar exactamente los mismos paquetes que se ejecutan en Windows Server Containers. Por lo tanto, la compensación de nivel de aislamiento versus eficiencia / agilidad es una decisión de tiempo de implementación, no una decisión de tiempo de desarrollo, una decisión tomada por el propietario del host.
Orquestación
A medida que adoptaron contenedores, los clientes descubrieron un desafío. Cuando implementan docenas, cientos o miles de contenedores que conforman una aplicación, el seguimiento y la administración de la implementación requieren avances en la administración y la orquestación. Container orchestration se ha convertido en una nueva e interesante área de innovación con múltiples opciones y soluciones. A los orquestadores de contenedores se les asigna un conjunto de servidores (VM o servidores bare metal), comúnmente llamados «clústeres», y «programación» la implementación de contenedores en esos servidores. Algunos orquestadores van más allá y configuran la conexión en red entre contenedores en diferentes servidores, mientras que algunos incluyen balanceo de carga, resolución de nombre de contenedor, actualizaciones continuas y más. Algunos son extensibles y permiten que los marcos de aplicación traigan estas capacidades adicionales. Si bien una discusión más profunda sobre las soluciones de orquestación podría requerir una publicación completa por sí misma, aquí hay un resumen breve de algunas de las tecnologías, todas compatibles con Azure:
Docker Compose permite la definición de aplicaciones simples de varios contenedores.
Docker Swarm administra y organiza contenedores Docker en varios hosts a través de la misma API utilizada por un solo host Docker.
Swarm y Compose se unen para ofrecer una tecnología de orquestación completa construida por Docker.
Mesos es una solución de orquestación y administración que, en realidad, es anterior a Docker, pero recientemente agregó soporte para Docker en su marco de aplicaciones integrado Marathon. Es una solución abierta y dirigida por la comunidad construida por Mesosphere. Recientemente demostramos la integración con Mesos y DCOS en Azure.
Kubernetes es una solución de código abierto creada por Google que ofrece agrupación de contenedores en «Pods» para la gestión en múltiples hosts. Esto también es compatible con Azure.
Deis es una plataforma de código abierto de PaaS para implementar y administrar aplicaciones integradas con Docker. Tenemos una manera fácil de implementar un clúster Deis en Azure.
Nos entusiasma contar con el respaldo de Azure para la mayoría de las soluciones de orquestación populares y esperamos involucrarnos más en estas comunidades a medida que aumenta el interés y el uso con el tiempo.
Microservicios
El uso más inmediato y lucrativo para los contenedores se ha centrado en simplificar DevOps con un desarrollador fácil para probar los flujos de producción de los servicios desplegados en la nube o en las instalaciones. Pero hay otro escenario en crecimiento donde los contenedores se vuelven muy convincentes. Microservicios es un enfoque para el desarrollo de aplicaciones donde cada parte de la aplicación se implementa como un componente completamente autónomo, llamado microservicio que se puede escalar y actualizar de forma individual. Por ejemplo, el subsistema de una aplicación que recibe solicitudes de Internet público puede estar separado del subsistema que pone la solicitud en una cola para que un subsistema de fondo pueda leerla y colocarla en una base de datos. Cuando la aplicación se construye utilizando microservicios, cada subsistema es un microservicio. En un entorno de desarrollo / prueba en un solo cuadro, los microservicios pueden tener una sola instancia, pero cuando se ejecutan en producción, cada uno puede escalar a diferentes números de instancias en un clúster de servidores según las demandas de recursos a medida que aumentan y disminuyen los niveles de solicitud del cliente. . Si los diferentes equipos los producen, los equipos también pueden actualizarlos de manera independiente. Microservicios no es un nuevo enfoque de programación, ni está vinculado explícitamente a contenedores, pero los beneficios de los contenedores Docker se magnifican cuando se aplican a una aplicación compleja basada en microervicios. Agilidad significa que un microservicio puede escalar rápidamente para cumplir con una mayor carga, el espacio de nombres y el aislamiento de recursos de contenedores evita que una instancia de microservicio interfiera con otros, y el uso del formato de empaque Docker y las API desbloquean el ecosistema Docker para el desarrollador de microservicios y el operador de aplicaciones . Con una buena arquitectura de microservicio, los clientes pueden resolver las necesidades de administración, implementación, orquestación y parcheo de un servicio basado en contenedores con un menor riesgo de pérdida de disponibilidad y al mismo tiempo mantener una gran agilidad. Hoy en día existen varias soluciones para crear modelos de aplicaciones que utilizan microservicios y nos asociamos con muchos de ellos en Azure. Docker Compose y Mesosphere Marathon son dos ejemplos. Poco antes de // build, anunciamos y luego lanzamos una vista previa de desarrollador de Service Fabric, nuestra propia plataforma de aplicaciones de microservicios. Incluye una amplia colección de capacidades de administración del ciclo de vida de microservicios, incluida la actualización continua con reversiones, particiones, restricciones de ubicación y más.
Cabe destacar que, además de los microservicios sin estado, es compatible con microservicios con estado, que se diferencian por el hecho de que el microservicio administra los datos que conviven con él en el mismo servidor. De hecho, Service Fabric es la única plataforma PaaS que ofrece microservicios con estado con administración de estado y marcos de replicación integrados directamente en su administración de clúster. Desarrollamos este modelo de aplicación para que los servicios internos puedan escalar a hiperescala con replicación con estado, y servicios como Cortana, Azure SQL Database y Skype for Business se basan en él. Lanzaremos una vista previa pública de Service Fabric a finales de este año, pero mientras tanto puedes consultar más en Service Fabric aquí. Espero que lo anterior ayude a dar una imagen útil de la visión de contenedores de Microsoft, los casos de uso de contenedores más comunes y también algunas de las tendencias emergentes de la industria en torno a los contenedores. Como siempre, nos encantaría recibir sus comentarios, especialmente si hay áreas en las que desea obtener más información.
JDA, Instalación Allocation
Documento Confidencial
Comentarios